
Project Visionaries - MMORPG
Update 14: Fog of War and Network issues
In this update, I'm going to focus on the following two topics: fog of war and server infrastructure (with a focus on networking and UDP routing).
Designing Fog of War
Shortly after my last update, I started messing around with a Fog Of War implementation based on Line of Sight. The main idea behind this is that I want players to be exploring the map as they go, and very much in the way that a real person would (i.e based on what they can directly see).
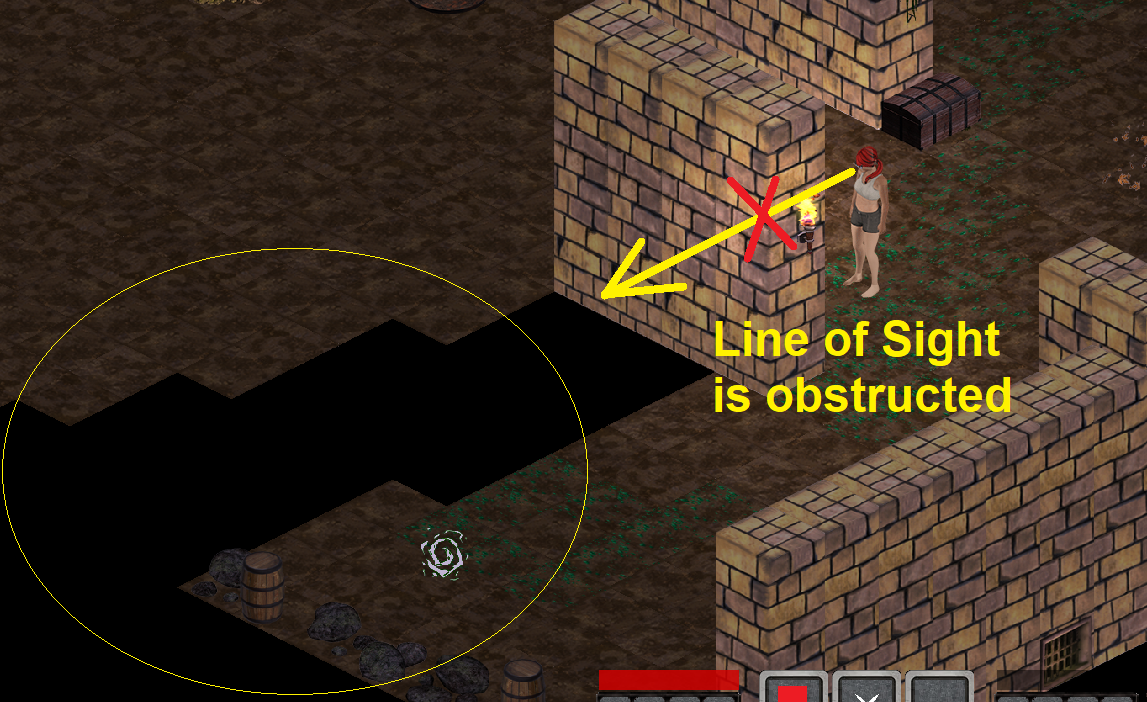
Of course, there has to be a limited distance regarding how far you can see/discover things. Currently, this distance is arbitrary but it might end up being influenced by a dynamic modifier - for instance, from your gear - kinda like light radius in D2. The visual look and general design is still very raw but it's a start and - I believe - a nice way of countering the fact that with (currently) unlimited scrolling, you could otherwise explore pretty much the entire map by scrolling out into a bird's eye type view.
Here's what it more or less looks like at the moment:
Notice there's a key departure from the D2 approach here: in D2, because of the general darkness and inability to zoom out, fog of war isn't really necessary. They still paid attention to details like line of sight and not being able to fully see what awaited you in the next room, but generally speaking, you could at least always see the map around your character.
I believe a Fog of war implementation alongside a highly permissive zoom will make for very interesting and different real-time gameplay, especially in scenarios such as open-map PK, if we decide to roll with that. Now, I'm planning on doing multiple passes on this and addressing things like the rough, black diamond-shaped pattern to make the darkness more subtle and progressive. I might also consider going for a more RTS-like approach with a black and a gray fog of war: one for initial exploration and the other for real-time visualization.
Dealing with UDP delay issues
Our second topic today has to do with infrastructure and in particular, networking. So back in December I decided to roll with kubernetes (k8s) for deploying, operating and updating server code in all regions. If you're interested, I actually covered this topic along with my Continuous Deployment strategy and other non-functional aspects back in update #4.
However, when I started scaling up the number of monsters present on the same map and the number of concurrent clients connected to the same world, clients started getting disconnected somewhat randomly (and more so if located behind a spotty connection, using wifi, etc). I spent some time investigating these issues and noticed often that Kryo would basically disconnect because of buffers becoming full. Yet, increasing buffer sizes never really solved the problem.
An important note here is that monster positions, similarly to player positions are sent every 16 ms to all clients over UDP (provided the monster/player moves which is the case more often than not).
Now, in my first, naive implementation of position updates, I basically iterated over all registered clients in that area and sent an individual message to each of these for EACH monster move. I knew at the time that this was likely to be an inefficient way of propagating updates and that one day I'd have to revisit this but it worked for a long time and was simply good enough in the early development stages. Until I started ramping up monsters and players numbers, that is.
So a few days ago, I decided the time had come to implement an optimization in which I'd start batching up position updates for all monsters and sending one "big" message containing all of the new positions to each client at once (still once per frame). I assumed this could only relieve the network, in particular UDP traffic, and be beneficial to the game's overall performance. That was only partially true. It was true on a local set up and as you can see on the following video, both monster movement and thrown skull motions are fluid:
But as soon as I deployed this patch to my kubernetes managed clusters over at OVH, monsters started stuttering and basically constantly lagging behind. I was able to tell that the lag was getting worse the more many monsters were in the area (i.e the bigger the size of the coordinate collection contained within the UDP message).
This is what the same thing looked like on k8s @ OVH:
It may not be too obvious if you're not used to the game patterns and because I had multiple clients open as part of my test, but you can see the monster's stutter-motion as well as skulls exploding BEFORE moving to their destination. That's because the explosion event is sent over TCP, which still worked fine, but motion events travel over UDP, and is noticeably delayed.
After profiling my client's and server's app code and making sure I hadn't introduced some kind of unrelated performance problem by accident, I started suspecting that either kubernetes or OVH's infrastructure or some combination of both of these factors made it so that larger UDP packets would be de-prioritized, slowed down or queued up somehow. And so, I decided to boot up a good ole, plain debian VM over at Exoscale and just installed docker on it to run my server (without kubernetes). This provided me with a more controlled technical environment, yet the server would still be running several network hops away across the internet (as opposed to locally on my own computer like in my first test).
And all of the sudden, the performance was good again! Better: my optimization seemed to have proven fruitful. In addition to position updates being responsive again, there were no more disconnection issues. I haven't actually rolled the code back to an earlier, pre-UDP-optimization state to check whether disconnections would still have happened on the Exoscale VM, but I'm just satisfied with the level of performance in the current state.
To test the server even further, I went ahead and asked a few playtesters to log on and each start a few clients and then play actively with one of them. Each passive client increases UDP traffic since it receives updates while each active client generates more computation and additional "critical" events usually routed over TCP. On this same map which still features 250 active monsters and with, I believe, 18 connected clients, 4 of which were active, the performance was great, as you can tell in this last bit of footage. I was single-handedly running 8 of these clients on my own PC. In the bottom left corner you can see nmon running, as I monitor network traffic, memory and CPU usage on the server VM.
The only bad news is that I'm now very likely to be ditching OVH and possibly kubernetes itself, which adds a substantial amount of complexity and I may have to redesign my whole server deployment logic and CI/CD chain.
Also, next time I have to mess with infrastructure and networking issues, I'm going to pause and take the time to automate these performance tests to "once and for all" assess the actual scalability of my game server instances. At this point my goal is to support at least 32 players and 250 monsters on the same map / screen and if I can double these numbers, I will.
That's all (for today), folks!
Leave a comment
Log in with itch.io to leave a comment.